Lorenz System Predictor
2022 / Course Final Project
Role:
Neural Network Designer
Date:
Spring 2022
Tools Used:
Python, PyTorch, CUDA
Design Overview
I worked in a team of four on a final project to combine concepts from two courses: Parallel Computing and Data Driven Dynamics. I was interested in learning more about the performance of different optimizing functions when training a neural network and wanted to consider the Lorenz system as an example. Our group also wanted to explore the benefit of parallelized computation when training the neural network on a GPU in comparison with serial computation when training on a CPU. Our team used the Python library PyTorch for the neural network development and Google Colab for GPU access. I was responsible for designing the neural network and running the serial implementation (training on the CPU). Another team member used the same neural network architecture, but used the PyTorch cuda device in order to train it on a GPU. This project gave me insight into tuning hyperparameters for neural networks, understanding how large neural networks have to be for speedup benefit from parallelization, and what optimizer functions perform better for learning nonlinear trajectories.
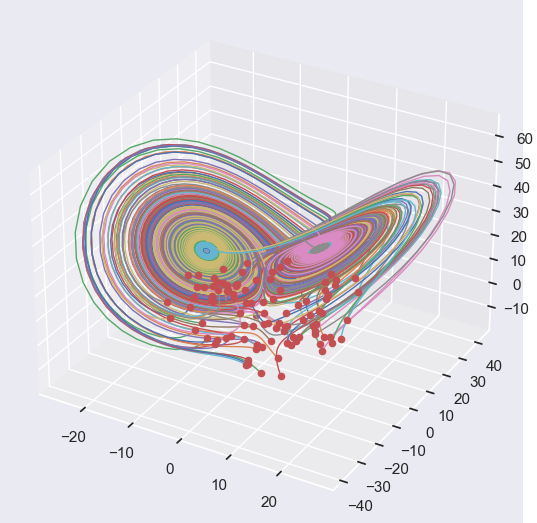
Background
Machine learning models use various mathematical optimization algorithms, such as gradient descent, to train a neural network to learn and predict the dynamics of a complex, nonlinear system. This can be seen in heat transfer and climate change applications or when studying physical systems that have unknown governing equations. These optimization algorithms reduce the model’s error in predictions. By accurately predicting the solutions to a system’s governing equations, we as engineers can better design for it. In this project, the Lorenz system is used as an example physical system.
Parallel computation has been used in other settings to accelerate training times for large neural networks since training requires running several computations simultaneously. Parallel computing capitalizes on the fact that a GPU has more processing cores than a CPU so more tasks can be run at the same time. Our group wanted to demonstrate this speed-up, however we underestimated just how big the neural network has to be to see an appreciative benefit.
Method and Results
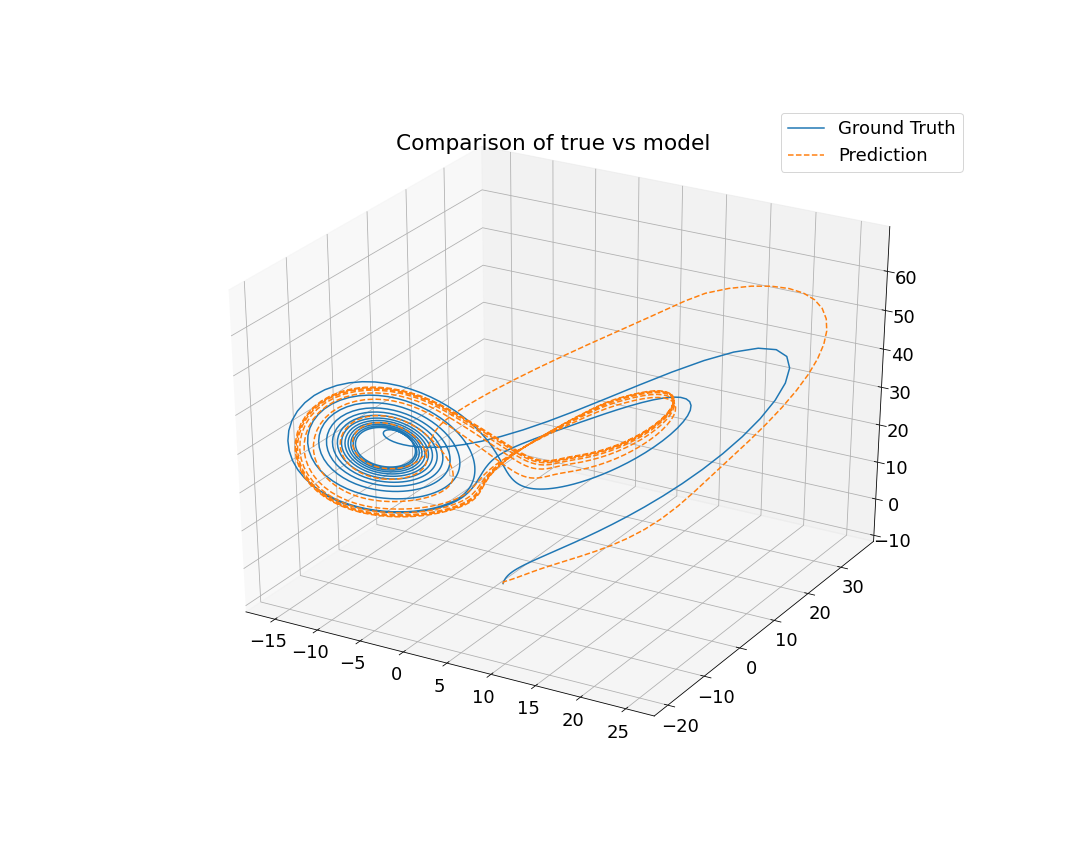
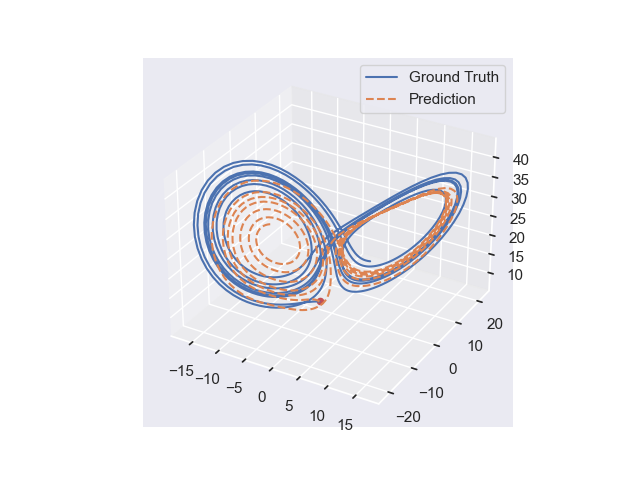
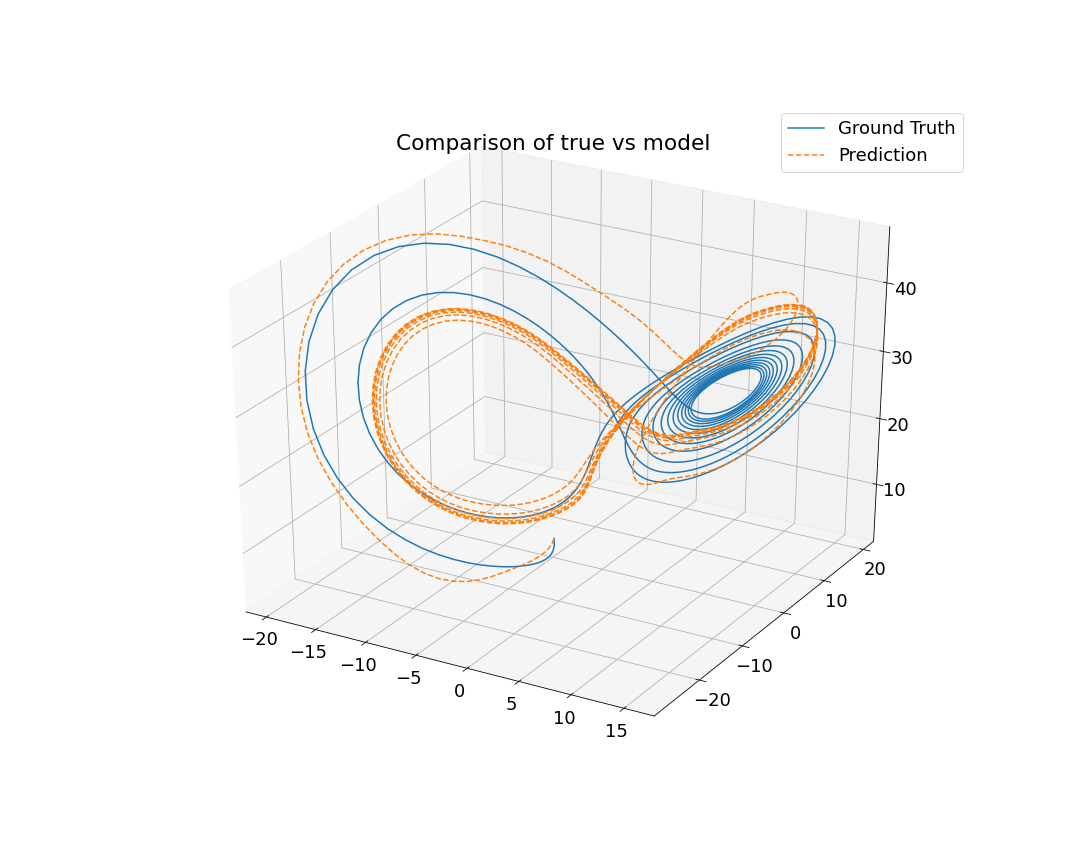
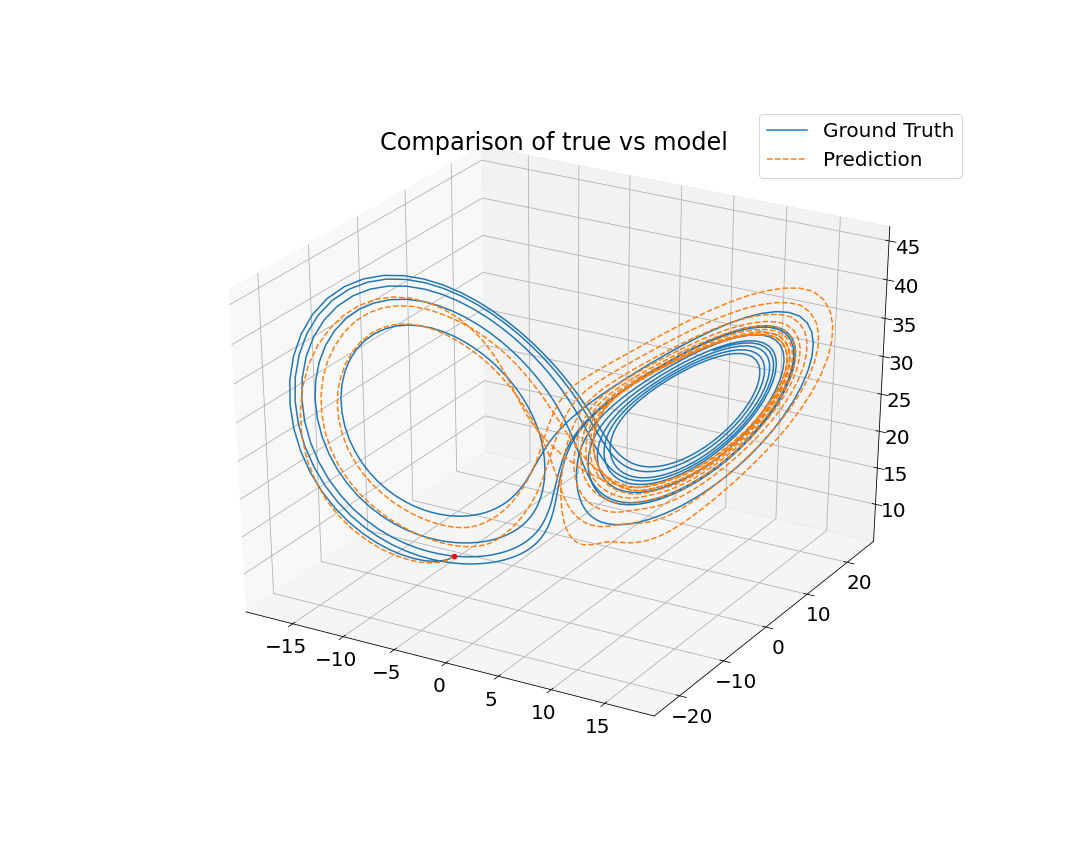
I was responsible for developing the neural network architecture that was used for both the serial and parallel implementations. I began by generating hundreds of solutions to the Lorenz system to use as ground truth training data. Next, I built the neural network. At this point there are several parameters that can be considered as design decisions: the size of the neural network, which optimization algorithm to use, and which activation function to use for each layer in the neural network. I chose to build a relatively small neural network in the interest of trying to keep the training time short. I used 2 hidden layers each with 10 neurons. The chosen activation function affects how well the neural network will be able to learn the pattern of the data (in this case, the nonlinear differential equations that define the Lorenz system). Because of this, I chose to use nonlinear activation functions (Sigmoid, Log Sigmoid, Rectified Linear Unit). There are many options for which optimizer to use, but I chose to experiment with two well-known optimizers: stochastic gradient descent (SGD) and Adam (which is an adaptive improvement on SGD). After training, I ran my model on a different set of randomly selected initial conditions for validation. Finally, I calculated the mean-squared error after each training and validation cycle to evaluate our model.
The predictions of our models, shown in the gallery below, reflect the limitations we imposed on ourselves. If we wrote our own optimizer instead of using what was pre-built in PyTorch, we would have seen more accurate results since the ones available in PyTorch are not ideal for our application. Furthermore, we could have experimented with other neural network architecture such as recursive neural networks. Ultimately, this project was an exploration in hyperparameter tuning and taught me about design considerations in neural network development.